
Abstract
These days, many efforts have been made to increase and develop the solubility and bioavailability of novel therapeutic medicines. One of the most believable approaches is the operation of supercritical carbon dioxide fluid (SC-CO2). This operation has been used as a unique method in pharmacology due to the brilliant positive points such as colorless nature, cost-effectives, and environmentally friendly. This research project is aimed to mathematically calculate the solubility of Oxaprozin in SC-CO2 through artificial intelligence. Oxaprozin is a nonsteroidal anti-inflammatory drug which is useful in arthritis disease to improve swelling and pain. Oxaprozin is a type of BCS class II (Biopharmaceutical Classification) drug with low solubility and bioavailability. Here in order to optimize and improve the solubility of Oxaprozin, three ensemble decision tree-based models including random forest (RF), Extremely random trees (ET), and gradient boosting (GB) are considered. 32 data vectors are used for this modeling, moreover, temperature and pressure as inputs, and drug solubility as output. Using the MSE metric, ET, RF, and GB illustrated error rates of 6.29E−09, 9.71E−09, and 3.78E−11. Then, using the R-squared metric, they demonstrated results including 0.999, 0.984, and 0.999, respectively. GB is selected as the best fitted model with the optimal values including 33.15 (K) for the temperature, 380.4 (bar) for the pressure and 0.001242 (mole fraction) as optimized value for the solubility.
Similar content being viewed by others
Introduction
Remarkable progression in pharmaceutical industry has paved the way towards creating novel therapeutic drugs for treating various challenging diseases1,2. Despite noteworthy development, poor solubility of active pharmaceutical ingredients (APIs) can be considered as the most prominent limitations for drug development3,4. Oxaprozin (C18H15NO3) can be recognized as one of the commonly-employed non-steroidal anti-inflammatory (NSAID) drug5,6. The analgesic and antipyretic characteristics of this propionic acid derivative has made it promising to appropriately alleviate the pain of acute/chronic disorders such as inflammation, swelling, osteoarthritis and rheumatoid arthritis7,8. Figure 1 presents the ball-stick demonstration of Oxaprozin. This NSAID drug possesses great ability to decline the formation of prostaglandin precursors from arachidonic acid via cyclo-oxygenase inhibition, which causes significant reduction in pain/inflammatory responses. Oxaprozin has shown superior efficacy compared to aspirin or piroxicam in the treatment of osteoarthritis9.

Schematic demonstration of Oxaprozin10.
To improve the solubility of drugs, the indisputable role of solvents can’t be ignored. These days, supercritical fluids (SCFs) are known as an innovative technique that demonstrates their efficiency for particle formation. This novel approach can overcome some disadvantages of conventional technologies such as crushing, crystallization and precipitation11,12. Supercritical carbon dioxide (SC-CO2) is being frequently applied to fractionate the precious components in pharmaceutical processes due to possessing noteworthy properties such as abundancy, colorless nature, cost-effectiveness, and environmentally benign characteristic13. Due to the importance of solubility in SC-CO2 for the design and development of novel drugs, the conduction of experimental investigation for evaluating the solubility of these drugs is of great importance14. Despite the great importance for obtaining the solubility of drugs, the existence of some economic/operational problems such as difficulty in solute–solvent interactions in SC-CO2 system and high cost have limited the conduction of experimental investigation.
Therefore, development of mathematical modeling approaches to predict the solubility amount of disparate types of drugs can be an appropriate option to optimize the time and cost of processing. Nowadays, AI has been introduced as a promising predictive tool to measure the solubility of drugs, numerically. Apart from pharmacology, AI has found its indisputable role in disparate knowledge related to chemical engineering such as extraction, purification, separation, crystallization and chemical reactor engineering15. In most scientific fields, machine learning (ML) techniques are known as common computational procedures, including regression trees, neural networks, support vector machines. A variety of relationships between inputs and outputs are extracted by these models16,17,18.
The Decision Tree (DT) is one of the typically used learning models. A weak model is a simple predictor that is only likely to be better than a random estimator. The results of many base DT models are aggregated to form a stronger model in tree-based ensemble methods19,20.
Bagging and boosting are two of the most effective improvement strategies with Decision Trees. Bagging (Bootstrap Aggregating), developed by Breiman21, is one of the most basic and straightforward ensemble techniques, demonstrating outstanding performance while reducing variance and preventing overfitting. The Bagging algorithm is more diverse because of the bootstrap approach, which replicates and generates subsets of training data. All of the subsets are used to fit different basic estimators, and the final prediction results are compiled using a majority-vote method21,22.
One other ensemble method based on the Freund and Schapiro’s study is boosting23. The aim of this research was optimization of Oxaprozin solubility within supercritical fluid by applying different machine learning models to find the best model for that.
By progressively reweighting the training data, this approach differs from Bagging in that it generates a diverse set of basic learners. A higher weight will be given to each sample whose estimation was weaker than the previous estimator's in the subsequent training step. As a result, in subsequent bootstrap samples, it is more likely that training samples with weak estimates will appear, allowing bias to be effectively removed. Based on their prediction performance, the base estimators are weighted in the final Boosting algorithm model. A random forest model, Extra Trees, and Gradient Boosting model were all considered for inclusion in this research24,25,26,27.
Experimental
Various predictive models in this research have been investigated and developed based on the experimental investigation of Khoshmaram et al. They experimentally measured the solubility of Oxaprozin using the combination of static and gravimetric techniques via a pressure–volume-temperature (PVT) cell14. This system can be filled with up to 0.4 L Oxaprozin and supercritical liquid. The adjustment of two momentous parameters for evaluating the solubility of drugs (temperature and pressure) in the PVT cell is an important advantage. In the PVT cell, increment of pressure causes the manufacturing of SC-CO2 in the liquefaction unit. Then, the condensed solvent moves through the inline filter with the aim of purifying the solvent. In the next step, purified solvent enters a surge tank before the PVT cell. The controlling process of SC-CO2 and Oxaprozin temperatures was implemented applying heating elements insulated by a PTFE layer.
Data set
This study's dataset is derived from14 that have just 32 data vectors. Each vector has two input parameters (pressure and temperature) and one output (solubility). The dataset is shown in Table 1 and Pearson correlation28 of parameters are shown in Fig. 2.

Pearson correlation plot.
Methodology
Random forest and extra tree
The random forest ensemble learning model is a tree-based technique that, like other ensemble learning methods, which is used to enhance the effectiveness of multiple base tree learners29. There will then be an unpruned regression tree built for every bootstrapped sample. This is what will happen next. Instead of using all the current predictors, a specified number of K base models are picked randomly to perform the function of split possibilities in this stage. This two-step operation will be iterated unto C decision trees with the above-mentioned characteristics are optimized, at which point unobserved data can be predicted by gathering the estimations of these C trees. Random forest uses a bagging strategy to boost tree diversity via constructing DTs using different training subsets, minimizing the model's total variance17. An RF regression predictor is expressed in the following equation:
According to the previous equation, C refers to the count of decision trees, x identifies the data point, and Ti(x) refers to a unique DT built from bootstrap samples and a subset of entry variables. RF can predict out-of-bag error for the time being logging natively using samples which have not been selected in connection with the drive of this shaft during the bagging process. To compute an unbiased prediction of distribution error, this particular sub-association does not make use of any external data19,30. Assign substantial scores to each input variable. RF modifies one input variable while holding the others constant, and the model's average decrease is also assigned19.
Extra Trees (ET) are an overall tree-based approach like random forest. It strongly randomize both the cut point decision and the particularities of a tree node during its division Extra Tree becomes possible to categorize and regression tasks31,32.
As far as the differences are concerned, the two models are identical in that they develop multiple trees and divide nodes applying random subsets of functions, nevertheless, there are two major separations exist: Rather than using optimum splits, the ET uses randomized splits instead of bootstrap observations33.
Gradient boosting
Boosting is also an ensemble learning technique. Boosting comprises a sequence of base predictors rather than a single predictor to average them all together to improve prediction accuracy. In a stage-wise process, base estimators (decision trees here) are successively fitted to eliminate bias. At each phase, a new learner is introduced to optimize the loss function. The first learner reduces the loss function to the smallest possible value using training data24,34,35. The residuals from the previous estimators are used by the following estimators. The gradient boosting method steps are depicted in the following Algorithm24,35,36:

Results
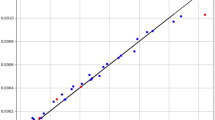
The tuning of the hyper-parameters of the mentioned models is based on a search grid. All three final models were evaluated by R-square and MSE criteria. Additionally, some visualization results were made, which will be discussed later. Figures 3, 4 and 5 show a comparison of expected values and predicted amounts. In the below figures, the blue line indicates the expected amounts and the points of the predicted values (red for the test data and black for the training data). In addition, Table 2 shows quantitative metrics to compare the three implemented models with the optimal hyper-parameters. Comparison of tabulated results in Table 2 has confirmed the fact that the GB is the most accurate and general model (R2 = 0.999 and MSE = 3.78E−11), which has been used as the main model for the rest of the analysis.

Expected and predicated solubility (ET model).

Expected and predicated solubility (RF model).

Expected and predicated solubility (GB model).
The simultaneous impacts of temperature and pressure as two prominent input parameters on the solubility as the only output is shown in 3D in Fig. 6. Furthermore, by holding each of the inputs fixed, the two-dimensional Figs. 7 and 8 are displayed. These figures correspond to the reality of the optimal values in Table 3. It can be perceived from the figures that the pressure of system has positive impact on the solubility of Oxaprozin in supercritical system. Indeed, increase in the pressure can improve the solvent density, which consequently intensifies the solvating power of the SC-CO2 system. Although pressure has direct connection with the solubility of drug, the impact of temperature is entirely indirect. To evaluate the effect of temperature on drug solubility, the role of sublimation pressure and density above and below the cross-over pressure (COP) must be analyzed. At the pressures above the COP, the encouraging influence of sublimation pressure on solubility dominates the deteriorative impact of density reduction. Therefore, at these pressures, temperature increment significantly enhances the solubility in SC-CO2 system. At pressures below the COP, the destructive impact of density decrement overcomes the positive effect of sublimation pressure. Therefore, at these amounts of pressures, increasing the temperature significantly reduces the solubility in SC-CO2. By concentrating on Table 3, it is recognized that the pressure and the temperature of 380.4 bar and 333.15 K are the optimum factors for reaching the greatest amount of Oxaprozin solubility.

Input–output projection (GB).

Solubility (mole fraction) based on pressure (bar), temperature (°K).

Solubility (mole fraction) base on temperature (°K), pressure (bar).
Conclusion
Now a days, numerous efforts have been made to develop green and efficient solvents to overcome the functional/operational detriments of organic solvents. Nowadays, SC-CO2 has been introduced as a prevalently employed liquid solvent to fractionate the valuable components and increase the solubility of drugs in pharmaceutical processes because of its remarkable advantages (i.e., abundancy, cost-effectives, and environmentally benign characteristic). In this paper, disparate types of numerical models were proposed via AI technique to anticipate the optimum value of Oxaprozin in SC-CO2. In this study, three ensemble decision tree-based models were used to model the problem: extremely random tree (ET), random forest (RF), and Gradient Tree Boosting (GB). This problem's available data consists of 32 data vectors with two inputs of temperature and pressure and an output of solubility. ET, RF, and GB had MSE error rates of 6.29E−09, 9.71E−09, and 3.78E−11. They also have R-squared scores of 0.999, 0.984, and 0.999, respectively. The final model chosen is GB, with the following optimal values: T = 33.15, P = 380.4, and solubility = 0.001242, which shows the greatest amount of Oxaprozin solubility.
Data availability
All data are available within the published paper.
Abbreviations
- SC-CO2 :
-
Supercritical carbon dioxide fluid
- AI:
-
Artificial intelligence
- NSAID:
-
Nonsteroidal anti-inflammatory
- RF:
-
Random forest
- GB:
-
Gradient boosting
- ET:
-
Extremely random trees
- ML:
-
Machine learning
- API:
-
Active pharmaceutical ingredient
- SCFs:
-
Supercritical fluids
- DT:
-
Decision tree
- COP:
-
Cross-over pressure
References
Zeng, X., Tu, X., Liu, Y., Fu, X. & Su, Y. Toward better drug discovery with knowledge graph. Curr. Opin. Struct. Biol. 72, 114–126 (2022).
Zhuang, W., Hachem, K., Bokov, D., Ansari, M. J. & Nakhjiri, A. T. Ionic liquids in pharmaceutical industry: A systematic review on applications and future perspectives. J. Mol. Liquids 349, 118145 (2021).
Chakravarty, P., Famili, A., Nagapudi, K. & Al-Sayah, M. A. Using supercritical fluid technology as a green alternative during the preparation of drug delivery systems. Pharmaceutics 11, 629 (2019).
Savjani, K. T., Gajjar, A. K. & Savjani, J. K. Drug solubility: Importance and enhancement techniques. Int. Sch. Res. Not. 2012 (2012).
Greenblatt, D. et al. Oxaprozin pharmacokinetics in the elderly. Br. J. Clin. Pharmacol. 19, 373–378 (1985).
Kean, W. F. Oxaprozin: Kinetic and Dynamic Profile in the Treatment of Pain 1275–1277 (Taylor & Francis, 2004).
Fischer, J. & Ganellin, C. R. Analogue-based drug discovery. Chem. Int. Newsmag. IUPAC 32, 12–15 (2010).
Ganellin, C. R. Analogue-Based Drug Discovery II (Wiley, 2010).
Miller, L. G. Oxaprozin: A once-daily nonsteroidal anti-inflammatory drug. Clin. Pharm. 11, 591–603 (1992).
File:Oxaprozin molecule ball.png. Wikimedia Commons, the Free Media Repository (2022). Retrieved 10:52, May 17, 2022 from https://commons.wikimedia.org/w/index.php?title=File:Oxaprozin_molecule_ball.png&oldid=644050983.
Baldelli, A., Boraey, M. A., Nobes, D. S. & Vehring, R. Analysis of the particle formation process of structured microparticles. Mol. Pharm. 12, 2562–2573 (2015).
Misra, S. K. & Pathak, K. Supercritical fluid technology for solubilization of poorly water soluble drugs via micro-and naonosized particle generation. ADMET DMPK 8, 355–374 (2020).
Bahramifar, N., Yamini, Y. & Shamsipur, M. Investigation on the supercritical carbon dioxide extraction of some polar drugs from spiked matrices and tablets. J. Supercrit. Fluids 35, 205–211 (2005).
Khoshmaram, A. et al. Supercritical process for preparation of nanomedicine: Oxaprozin case study. Chem. Eng. Technol. 44, 208–212 (2021).
Chinh Nguyen, H. et al. Computational prediction of drug solubility in supercritical carbon dioxide: Thermodynamic and artificial intelligence modeling. J. Mol. Liquids 354, 118888 (2022).
Bishop, C. M. Pattern recognition. Mach. Learn. 128 (2006).
Rodriguez-Galiano, V., Sanchez-Castillo, M., Chica-Olmo, M. & Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 71, 804–818 (2015).
Goodfellow, I., Bengio, Y. & Courville, A. Machine learning basics. Deep Learn. 1, 98–164 (2016).
Breiman, L., Friedman, J. H., Olshen, R. A. & Stone, C. J. Classification and Regression Trees (Routledge, 2017).
Xue, M., Su, Y., Li, C., Wang, S. & Yao, H. Identification of potential type II diabetes in a large-scale Chinese population using a systematic machine learning framework. J. Diabetes Res. 2020 (2020).
Breiman, L. Bagging predictors. Mach. Learn. 24, 123–140 (1996).
Borra, S. & Di Ciaccio, A. Improving nonparametric regression methods by bagging and boosting. Comput. Stat. Data Anal. 38, 407–420 (2002).
Freund, Y. & Schapire, R. E. Experiments with a new boosting algorithm. In ICML 148–156 (Citeseer, 1996).
Mason, L., Baxter, J., Bartlett, P. & Frean, M. Boosting algorithms as gradient descent. Adv. Neural Inf. Process. Syst. 12 (1999).
Pardoe, D. & Stone, P. Boosting for regression transfer. In ICML (2010).
Wu, Q., Burges, C. J., Svore, K. M. & Gao, J. Adapting boosting for information retrieval measures. Inf. Retr. 13, 254–270 (2010).
Ying, C., Qi-Guang, M., Jia-Chen, L. & Lin, G. Advance and prospects of AdaBoost algorithm. Acta Autom. Sin. 39, 745–758 (2013).
Benesty, J., Chen, J., Huang, Y. & Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing 1–4 (Springer, 2009).
Jiang, R., Tang, W., Wu, X. & Fu, W. A random forest approach to the detection of epistatic interactions in case–control studies. BMC Bioinform. 10, 1–12 (2009).
Zhang, J. et al. Rapid evaluation of texture parameters of Tan mutton using hyperspectral imaging with optimization algorithms. Food Control 135, 108815 (2022).
Geurts, P., Ernst, D. & Wehenkel, L. Extremely randomized trees. Mach. Learn. 63, 3–42 (2006).
Dutta, S., Mukherjee, U. & Bandyopadhyay, S. K. Pharmacy impact on Covid-19 vaccination progress using machine learning approach. J. Pharm. Res. Int. 33, 202–217 (2021).
Song, Y.-Y. & Ying, L. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 27, 130 (2015).
Friedman, J. H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 29, 1189–1232 (2001).
Truong, V.-H., Vu, Q.-V., Thai, H.-T. & Ha, M.-H. A robust method for safety evaluation of steel trusses using gradient tree boosting algorithm. Adv. Eng. Softw. 147, 102825 (2020).
Xu, Q. et al. PDC-SGB: Prediction of effective drug combinations using a stochastic gradient boosting algorithm. J. Theor. Biol. 417, 1–7 (2017).
Acknowledgements
The author would like to extend their science appreciation to Taif university Researchers Supporting Project Number (TURSP-2020/309), Taif University, Taif Saudi Arabia. The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through Large Groups Project under grant number (RGP2/50/43). The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for Supporting this work by Grant code (22UQU4290565DSR45).
Author information
Authors and Affiliations
Contributions
S.A.: supervision, software, data analysis, validation, modeling, original draft writing, methodology. M.A.: investigation, original draft writing, data analysis, methodology. N.I.N.: writing and editing, data analysis, investigation, conceptualization. I.A.N.: writing and editing, methodology, data analysis, investigation, validation, conceptualization. K.V.: investigation, original draft writing, data analysis, methodology. Y.O.M.: writing and editing, modeling and validation, data analysis, investigation, conceptualization. M.P.: supervision, software, data analysis, validation, modeling, original draft writing, methodology. A.M.A.: investigation, writing, editing, data analysis, validation. M.A.S.A.: supervision, data analysis, validation, original draft writing, methodology.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Alshehri, S., Alqarni, M., Namazi, N.I. et al. Design of predictive model to optimize the solubility of Oxaprozin as nonsteroidal anti-inflammatory drug. Sci Rep 12, 13106 (2022). https://doi.org/10.1038/s41598-022-17350-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-17350-5
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.

{kind=link}